Models Reference¶
Available Models¶
Segmentation¶
STFPM (Supports OpenVINO)
Classification¶
Loading Models¶
DFKDE¶
Model Type: Classification
Description¶
Fast anomaly classification algorithm that consists of a deep feature extraction stage followed by anomaly classification stage consisting of PCA and Gaussian Kernel Density Estimation.
Feature Extraction¶
Features are extracted by feeding the images through a ResNet50 backbone, which was pre-trained on ImageNet. The output of the penultimate layer (average pooling layer) of the network is used to obtain a semantic feature vector with a fixed length of 2048.
Anomaly Detection¶
In the anomaly classification stage, the features are first reduced to the first 16 principal components. Gaussian Kernel Density is then used to obtain an estimate of the probability density of new examples, based on the collection of training features obtained during the training phase.
Usage¶
$ python tools/train.py --model dfkde
DFM¶
This is the implementation of DFM paper.
Model Type: Classification
Description¶
Fast anomaly classification algorithm that consists of a deep feature extraction stage followed by anomaly classification stage consisting of PCA and class-conditional Gaussian Density Estimation.
Feature Extraction¶
Features are extracted by feeding the images through a ResNet18 backbone, which was pre-trained on ImageNet. The output of the penultimate layer (average pooling layer) of the network is used to obtain a semantic feature vector with a fixed length of 2048.
Anomaly Detection¶
In the anomaly classification stage, class-conditional PCA transformations and Gaussian Density models are learned. Two types of scores are calculated (i) Feature-reconstruction scores (norm of the difference between the high-dimensional pre-image of a reduced dimension feature and the original high-dimensional feature), and (ii) Negative log-likelihood under the learnt density models. Either of these scores can be used for anomaly detection.
Usage¶
$ python tools/train.py --model dfm
GANomaly —
This is the implementation of the GANomaly paper.
Description¶
GANomaly uses the conditional GAN approach to train a Generator to produce images of the normal data. This Generator consists of an encoder-decoder-encoder architecture to generate the normal images. The distance between the latent vector $z$ between the first encoder-decoder and the output vector $hat{z}$ is minimized during training.
The key idea here is that, during inference, when an anomalous image is passed through the first encoder the latent vector $z$ will not be able to capture the data correctly. This would leave to poor reconstruction $hat{x}$ thus resulting in a very different $hat{z}$. The difference between $z$ and $hat{z}$ gives the anomaly score.
Usage¶
$ python tools/train.py --model ganomaly
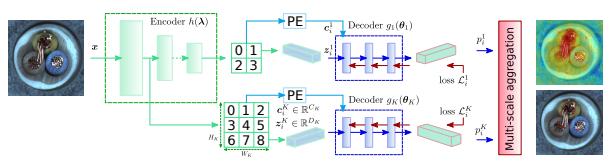
CFlow¶
This is the implementation of the CFlow paper.
Model Type: Segmentation
Description¶
CFLOW model is based on a conditional normalizing flow framework adopted for anomaly detection with localization. It consists of a discriminatively pretrained encoder followed by a multi-scale generative decoders. The encoder extracts features with multi-scale pyramid pooling to capture both global and local semantic information with the growing from top to bottom receptive fields. Pooled features are processed by a set of decoders to explicitly estimate likelihood of the encoded features. The estimated multi-scale likelyhoods are upsampled to input size and added up to produce the anomaly map.
Architecture¶
Usage¶
$ python tools/train.py –model cflow
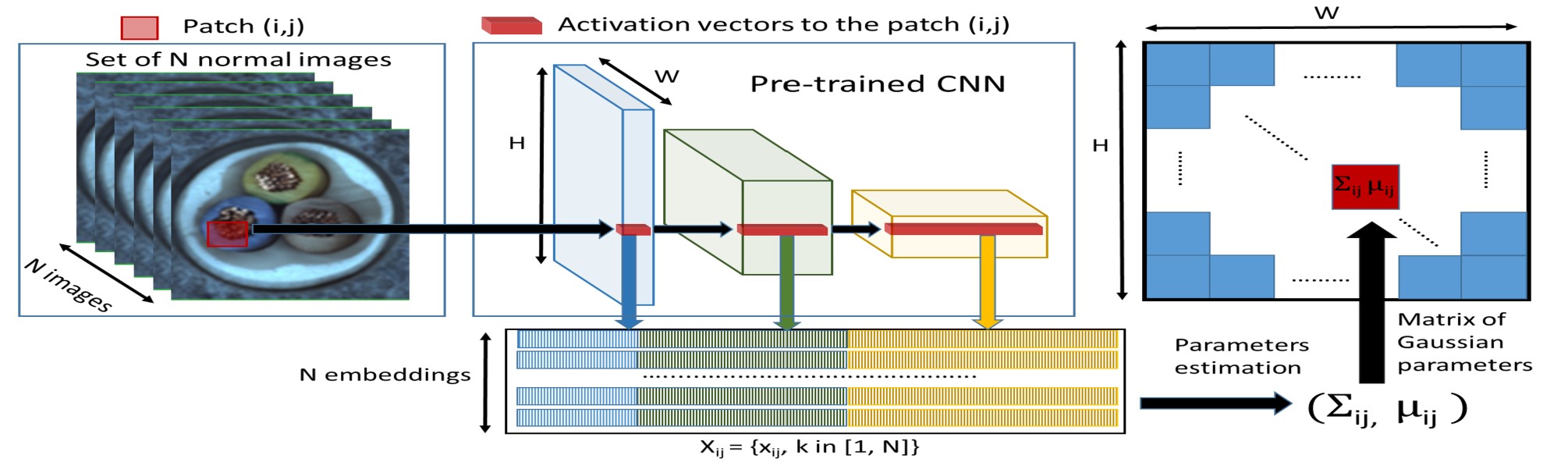
Padim¶
This is the implementation of the PaDiM paper.
Model Type: Segmentation
Description¶
PaDiM is a patch based algorithm. It relies on a pre-trained CNN feature extractor. The image is broken into patches and embeddings are extracted from each patch using different layers of the feature extractors. The activation vectors from different layers are concatenated to get embedding vectors carrying information from different semantic levels and resolutions. This helps encode fine grained and global contexts. However, since the generated embedding vectors may carry redundant information, dimensions are reduced using random selection. A multivariate gaussian distribution is generated for each patch embedding across the entire training batch. Thus, for each patch of the set of training images, we have a different multivariate gaussian distribution. These gaussian distributions are represented as a matrix of gaussian parameters.
During inference, Mahalanobis distance is used to score each patch position of the test image. It uses the inverse of the covariance matrix calculated for the patch during training. The matrix of Mahalanobis distances forms the anomaly map with higher scores indicating anomalous regions.
Architecture¶
Usage¶
$ python tools/train.py --model padim
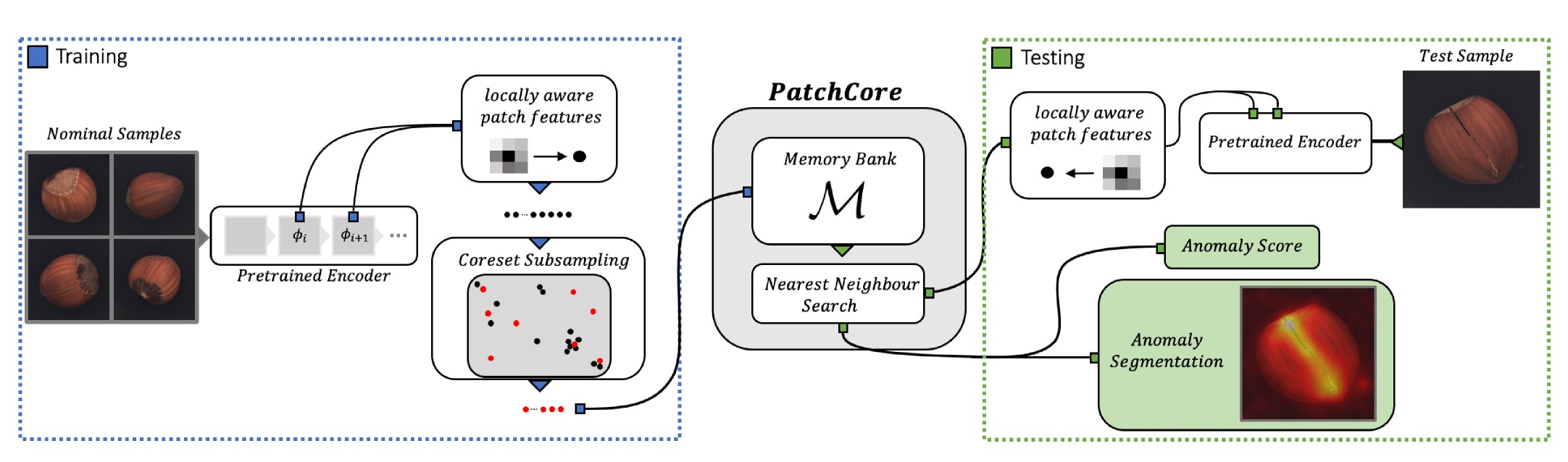
PatchCore¶
This is the implementation of the PatchCore paper.
Model Type: Segmentation
Description¶
The PatchCore algorithm is based on the idea that an image can be classified as anomalous as soon as a single patch is anomalous. The input image is tiled. These tiles act as patches which are fed into the neural network. It consists of a single pre-trained network which is used to extract “mid” level features patches. The “mid” level here refers to the feature extraction layer of the neural network model. Lower level features are generally too broad and higher level features are specific to the dataset the model is trained on. The features extracted during training phase are stored in a memory bank of neighbourhood aware patch level features.
During inference this memory bank is coreset subsampled. Coreset subsampling generates a subset which best approximates the structure of the available set and allows for approximate solution finding. This subset helps reduce the search cost associated with nearest neighbour search. The anomaly score is taken as the maximum distance between the test patch in the test patch collection to each respective nearest neighbour.
Architecture¶
Usage¶
$ python tools/train.py --model patchcore
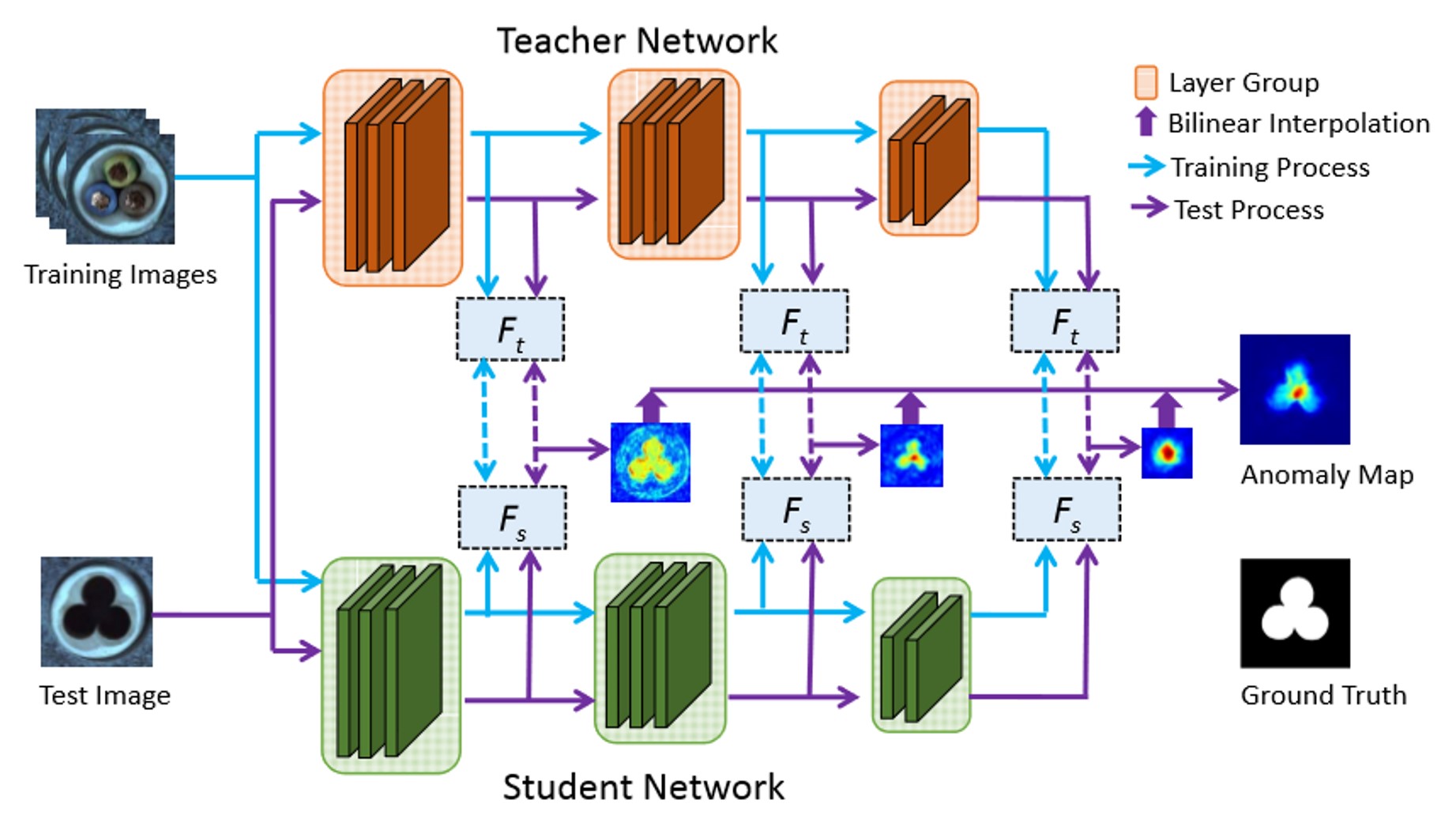
STFPM¶
This is the implementation of the STFPM paper.
Model Type: Segmentation
Description¶
STFPM algorithm which consists of a pre-trained teacher network and a student network with identical architecture. The student network learns the distribution of anomaly-free images by matching the features with the counterpart features in the teacher network. Multi-scale feature matching is used to enhance robustness. This hierarchical feature matching enables the student network to receive a mixture of multi-level knowledge from the feature pyramid thus allowing for anomaly detection of various sizes.
During inference, the feature pyramids of teacher and student networks are compared. Larger difference indicates a higher probability of anomaly occurrence.
Architecture¶
Usage¶
$ python tools/train.py --model stfpm
Reverse Distillation¶
This is the implementation of the Anomaly Detection via Reverse Distillation from One-Class Embedding paper.
Model Type: Segmentation
Description¶
Reverse Distillation model consists of three networks. The first is a pre-trained feature extractor (E). The next two are the one-class bottleneck embedding (OCBE) and the student decoder network (D). The backbone E is a ResNet model pre-trained on ImageNet dataset. During the forward pass, features from three ResNet block are extracted. These features are encoded by concatenating the three feature maps using the multi-scale feature fusion block of OCBE and passed to the decoder D. The decoder network is symmetrical to the feature extractor but reversed. During training, outputs from these symmetrical blocks are forced to be similar to the corresponding feature extractor layers by using cosine distance as the loss metric.
During testing, a similar step is followed but this time the cosine distance between the feature maps is used to indicate the presence of anomalies. The distance maps from all the three layers are up-sampled to the image size and added (or multiplied) to produce the final feature map. Gaussian blur is applied to the output map to make it smoother. Finally, the anomaly map is generated by applying min-max normalization on the output map.
Architecture¶

Usage¶
$ python tools/train.py --model reverse_distillation