Padim#
Architecture#
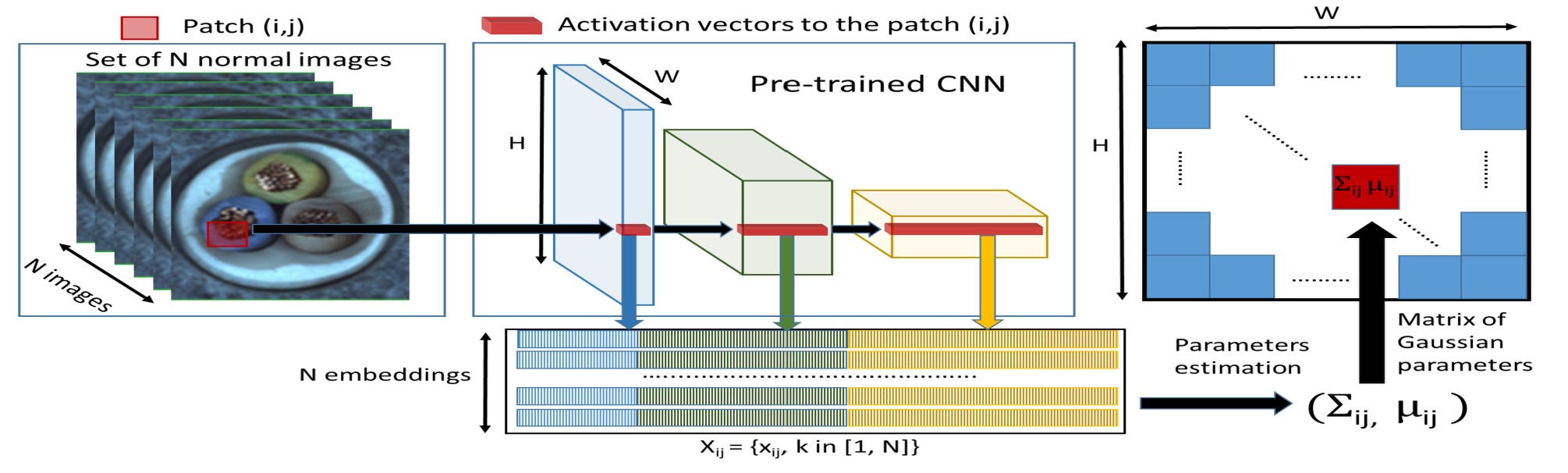
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization.
This model implements the PaDiM algorithm for anomaly detection and localization. PaDiM models the distribution of patch embeddings at each spatial location using multivariate Gaussian distributions.
The model extracts features from multiple layers of pretrained CNN backbones to capture both semantic and low-level visual information. During inference, it computes Mahalanobis distances between test patch embeddings and their corresponding reference distributions.
Paper: https://arxiv.org/abs/2011.08785
Example
>>> from anomalib.data import MVTecAD
>>> from anomalib.models.image.padim import Padim
>>> from anomalib.engine import Engine
>>> # Initialize model and data
>>> datamodule = MVTecAD()
>>> model = Padim(
... backbone="resnet18",
... layers=["layer1", "layer2", "layer3"],
... pre_trained=True
... )
>>> # Train using the Engine
>>> engine = Engine()
>>> engine.fit(model=model, datamodule=datamodule)
>>> # Get predictions
>>> predictions = engine.predict(model=model, datamodule=datamodule)
See also
anomalib.models.image.padim.torch_model.PadimModel:PyTorch implementation of the PaDiM model architecture
anomalib.models.image.padim.anomaly_map.AnomalyMapGenerator:Anomaly map generation for PaDiM using Mahalanobis distance
- class anomalib.models.image.padim.lightning_model.Padim(backbone='resnet18', layers=['layer1', 'layer2', 'layer3'], pre_trained=True, n_features=None, pre_processor=True, post_processor=True, evaluator=True, visualizer=True)#
Bases:
MemoryBankMixin,AnomalibModulePaDiM: a Patch Distribution Modeling Framework for Anomaly Detection.
- Parameters:
backbone (
str) – Name of the backbone CNN network. Available options areresnet18,wide_resnet50_2etc. Defaults toresnet18.layers (
list[str]) – List of layer names to extract features from the backbone CNN. Defaults to["layer1", "layer2", "layer3"].pre_trained (
bool) – Use pre-trained backbone weights. Defaults toTrue.n_features (
int|None) – Number of features to retain after dimension reduction. Default values from paper:resnet18=100,wide_resnet50_2=550. Defaults toNone.pre_processor (
Module|bool) – Preprocessor to apply on input data. Defaults toTrue.post_processor (
Module|bool) – Post processor to apply on model outputs. Defaults toTrue.evaluator (
Evaluator|bool) – Evaluator for computing metrics. Defaults toTrue.visualizer (
Visualizer|bool) – Visualizer for generating result images. Defaults toTrue.
Example
>>> from anomalib.models import Padim >>> from anomalib.data import MVTecAD >>> from anomalib.engine import Engine
>>> # Initialize model and data >>> datamodule = MVTecAD() >>> model = Padim( ... backbone="resnet18", ... layers=["layer1", "layer2", "layer3"], ... pre_trained=True ... )
>>> engine = Engine() >>> engine.train(model=model, datamodule=datamodule) >>> predictions = engine.predict(model=model, datamodule=datamodule)
Note
The model does not require training in the traditional sense. It fits Gaussian distributions to the extracted features during the training phase.
- static configure_optimizers()#
PADIM doesn’t require optimization, therefore returns no optimizers.
- Return type:
- static configure_post_processor()#
Return the default post-processor for PADIM.
- Returns:
Default post-processor
- Return type:
- property learning_type: LearningType#
Return the learning type of the model.
- Returns:
Learning type (ONE_CLASS for PaDiM)
- Return type:
LearningType
- training_step(batch, *args, **kwargs)#
Perform the training step of PADIM.
For each batch, hierarchical features are extracted from the CNN.
- validation_step(batch, *args, **kwargs)#
Perform a validation step of PADIM.
Similar to the training step, hierarchical features are extracted from the CNN for each batch.
- Parameters:
batch (
Batch) – Input batch containing image and metadataargs – Additional arguments (unused)
kwargs – Additional keyword arguments (unused)
- Returns:
Dictionary containing images, features, true labels and masks required for validation
- Return type:
PyTorch model for the PaDiM model implementation.
This module implements the PaDiM model architecture using PyTorch. PaDiM models the distribution of patch embeddings at each spatial location using multivariate Gaussian distributions.
The model extracts features from multiple layers of pretrained CNN backbones to capture both semantic and low-level visual information. During inference, it computes Mahalanobis distances between test patch embeddings and their corresponding reference distributions.
Example
>>> from anomalib.models.image.padim.torch_model import PadimModel
>>> model = PadimModel(
... backbone="resnet18",
... layers=["layer1", "layer2", "layer3"],
... pre_trained=True,
... n_features=100
... )
>>> input_tensor = torch.randn(32, 3, 224, 224)
>>> output = model(input_tensor)
Paper: https://arxiv.org/abs/2011.08785
See also
anomalib.models.image.padim.lightning_model.Padim:Lightning implementation of the PaDiM model
anomalib.models.image.padim.anomaly_map.AnomalyMapGenerator:Anomaly map generation for PaDiM using Mahalanobis distance
anomalib.models.components.MultiVariateGaussian:Multivariate Gaussian distribution modeling
- class anomalib.models.image.padim.torch_model.PadimModel(backbone='resnet18', layers=['layer1', 'layer2', 'layer3'], pre_trained=True, n_features=None)#
Bases:
ModulePadim Module.
- Parameters:
backbone (
str) – Pre-trained model backbone. Defaults toresnet18.pre_trained (
bool) – Boolean to check whether to use a pre_trained backbone. Defaults toTrue.n_features (
int|None) – Number of features to retain in the dimension reduction step. Default values from the paper are available for: resnet18 (100), wide_resnet50_2 (550). Defaults toNone.
- fit()#
Fits a Gaussian model to the current contents of the memory bank.
This method is typically called after the memory bank has been filled during training.
After fitting, the memory bank is cleared to free GPU memory before validation or testing.
- Raises:
ValueError – If the memory bank is empty.
- Return type:
- forward(input_tensor)#
Forward-pass image-batch (N, C, H, W) into model to extract features.
- Parameters:
input_tensor (
Tensor) – Image batch with shape (N, C, H, W)- Returns:
- If training, returns the embeddings.
If inference, returns
InferenceBatchcontaining prediction scores and anomaly maps.
- Return type:
Example
>>> model = PadimModel() >>> x = torch.randn(32, 3, 224, 224) >>> features = model.extract_features(x) >>> features.keys() dict_keys(['layer1', 'layer2', 'layer3']) >>> [v.shape for v in features.values()] [torch.Size([32, 64, 56, 56]), torch.Size([32, 128, 28, 28]), torch.Size([32, 256, 14, 14])]
- generate_embedding(features)#
Generate embedding from hierarchical feature map.
This method combines features from multiple layers of the backbone network to create a rich embedding that captures both low-level and high-level image features.