PatchCore#
Architecture#
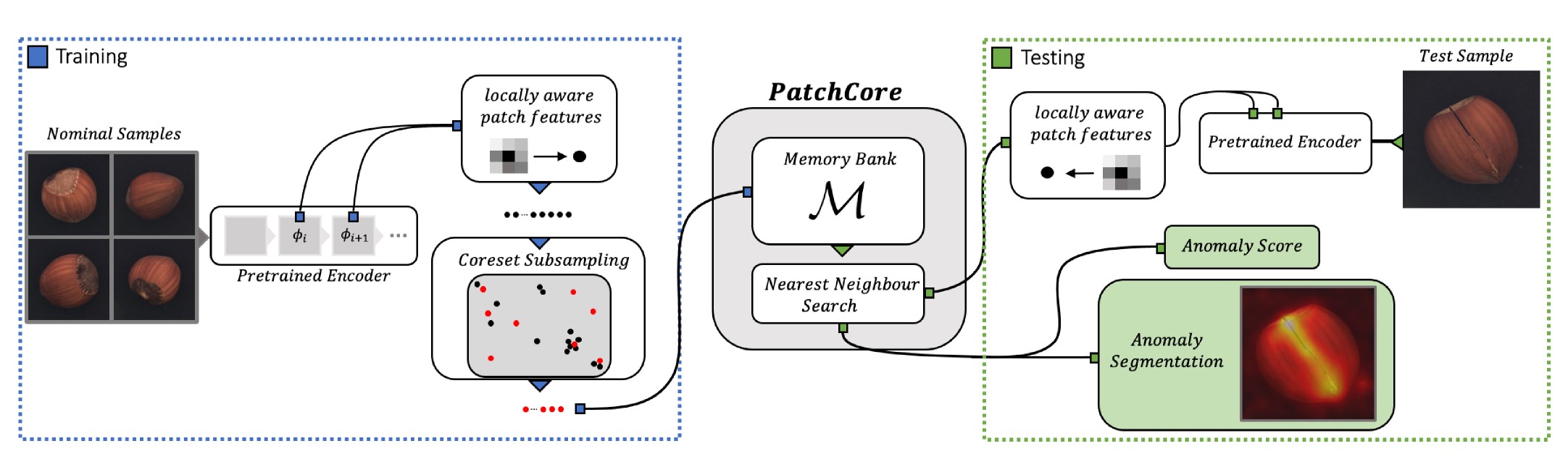
PatchCore: Towards Total Recall in Industrial Anomaly Detection.
This module implements the PatchCore model for anomaly detection using a memory bank of patch features extracted from a pretrained CNN backbone. The model stores representative patch features from normal training images and detects anomalies by comparing test image patches against this memory bank.
The model uses a nearest neighbor search to find the most similar patches in the memory bank and computes anomaly scores based on these distances. It achieves high performance while maintaining interpretability through localization maps.
Example
>>> from anomalib.data import MVTecAD
>>> from anomalib.models import Patchcore
>>> from anomalib.engine import Engine
>>> # Initialize model and data
>>> datamodule = MVTecAD()
>>> model = Patchcore(
... backbone="wide_resnet50_2",
... layers=["layer2", "layer3"],
... coreset_sampling_ratio=0.1
... )
>>> # Train using the Engine
>>> engine = Engine()
>>> engine.fit(model=model, datamodule=datamodule)
>>> # Get predictions
>>> predictions = engine.predict(model=model, datamodule=datamodule)
>>> # Configure pre-processor to reproduce paper settings
>>> pre_processor = Patchcore.configure_pre_processor(
... image_size=(256, 256),
... center_crop_size=(224, 224)
... )
Paper: https://arxiv.org/abs/2106.08265
See also
anomalib.models.image.patchcore.torch_model.PatchcoreModel:PyTorch implementation of the PatchCore model architecture
anomalib.models.image.patchcore.anomaly_map.AnomalyMapGenerator:Anomaly map generation for PatchCore using nearest neighbor search
- class anomalib.models.image.patchcore.lightning_model.Patchcore(backbone='wide_resnet50_2', layers=('layer2', 'layer3'), pre_trained=True, coreset_sampling_ratio=0.1, num_neighbors=9, precision=PrecisionType.FLOAT32, pre_processor=True, post_processor=True, evaluator=True, visualizer=True)#
Bases:
MemoryBankMixin,AnomalibModulePatchCore Lightning Module for anomaly detection.
This class implements the PatchCore algorithm which uses a memory bank of patch features for anomaly detection. Features are extracted from a pretrained CNN backbone and stored in a memory bank. Anomalies are detected by comparing test image patches with the stored features using nearest neighbor search.
The model works in two phases: 1. Training: Extract and store patch features from normal training images 2. Inference: Compare test image patches against stored features to detect
anomalies
- Parameters:
backbone (
str) – Name of the backbone CNN network. Defaults to"wide_resnet50_2".layers (
Sequence[str]) – Names of layers to extract features from. Defaults to("layer2", "layer3").pre_trained (
bool) – Whether to use pre-trained backbone weights. Defaults toTrue.coreset_sampling_ratio (
float) – Ratio for coreset sampling to subsample embeddings. Defaults to0.1.num_neighbors (
int) – Number of nearest neighbors to use. Defaults to9.precision (
str|PrecisionType) – Precision type for model computations. Can be either a string ("float32","float16") or aPrecisionTypeenum value. Defaults toPrecisionType.FLOAT32.pre_processor (
Module|bool) – Pre-processor instance or bool flag. Defaults toTrue.post_processor (
Module|bool) – Post-processor instance or bool flag. Defaults toTrue.evaluator (
Evaluator|bool) – Evaluator instance or bool flag. Defaults toTrue.visualizer (
Visualizer|bool) – Visualizer instance or bool flag. Defaults toTrue.
Example
>>> from anomalib.data import MVTecAD >>> from anomalib.models import Patchcore >>> from anomalib.engine import Engine
>>> # Initialize model and data >>> datamodule = MVTecAD() >>> model = Patchcore( ... backbone="wide_resnet50_2", ... layers=["layer2", "layer3"], ... coreset_sampling_ratio=0.1, ... precision="float32", ... )
>>> # Train using the Engine >>> engine = Engine() >>> engine.fit(model=model, datamodule=datamodule)
>>> # Get predictions >>> predictions = engine.predict(model=model, datamodule=datamodule)
Notes
The model requires no optimization/backpropagation as it uses a pretrained backbone and nearest neighbor search.
See also
anomalib.models.components.AnomalibModule:Base class for all anomaly detection models
anomalib.models.components.MemoryBankMixin:Mixin class for models using feature memory banks
- static configure_optimizers()#
Configure optimizers.
- Returns:
PatchCore requires no optimization.
- Return type:
- static configure_post_processor()#
Configure the default post-processor.
- Returns:
- Post-processor for one-class models that
converts raw scores to anomaly predictions
- Return type:
- classmethod configure_pre_processor(image_size=None, center_crop_size=None)#
Configure the default pre-processor for PatchCore.
If valid center_crop_size is provided, the pre-processor will also perform center cropping, according to the paper.
- Parameters:
- Returns:
Configured pre-processor instance.
- Return type:
- Raises:
ValueError – If at least one dimension of
center_crop_sizeis larger than correspondentimage_sizedimension.
Example
>>> pre_processor = Patchcore.configure_pre_processor( ... image_size=(256, 256) ... ) >>> transformed_image = pre_processor(image)
- fit()#
Apply subsampling to the embedding collected from the training set.
This method: 1. Applies coreset subsampling to reduce memory requirements
- Return type:
- property learning_type: LearningType#
Get the learning type.
- Returns:
- Always
LearningType.ONE_CLASSas PatchCore only trains on normal samples
- Always
- Return type:
LearningType
- training_step(batch, *args, **kwargs)#
Generate feature embedding of the batch.
- Parameters:
batch (
Batch) – Input batch containing image and metadata*args – Additional arguments (unused)
**kwargs – Additional keyword arguments (unused)
- Returns:
Dummy loss tensor for Lightning compatibility
- Return type:
Note
The method stores embeddings in
self.embeddingsfor later use infit().
- validation_step(batch, *args, **kwargs)#
Generate predictions for a batch of images.
- Parameters:
batch (
Batch) – Input batch containing images and metadata*args – Additional arguments (unused)
**kwargs – Additional keyword arguments (unused)
- Returns:
Batch with added predictions
- Return type:
Note
Predictions include anomaly maps and scores computed using nearest neighbor search.
PyTorch model for the PatchCore model implementation.
This module implements the PatchCore model architecture using PyTorch. PatchCore uses a memory bank of patch features extracted from a pretrained CNN backbone to detect anomalies.
The model stores representative patch features from normal training images and detects anomalies by comparing test image patches against this memory bank using nearest neighbor search.
Example
>>> from anomalib.models.image.patchcore.torch_model import PatchcoreModel
>>> model = PatchcoreModel(
... backbone="wide_resnet50_2",
... layers=["layer2", "layer3"],
... pre_trained=True,
... num_neighbors=9
... )
>>> input_tensor = torch.randn(32, 3, 224, 224)
>>> output = model(input_tensor)
Paper: https://arxiv.org/abs/2106.08265
See also
anomalib.models.image.patchcore.lightning_model.Patchcore:Lightning implementation of the PatchCore model
anomalib.models.image.patchcore.anomaly_map.AnomalyMapGenerator:Anomaly map generation for PatchCore using nearest neighbor search
anomalib.models.components.KCenterGreedy:Coreset subsampling using k-center-greedy approach
- class anomalib.models.image.patchcore.torch_model.PatchcoreModel(layers, backbone='wide_resnet50_2', pre_trained=True, num_neighbors=9)#
Bases:
DynamicBufferMixin,ModulePatchCore PyTorch model for anomaly detection.
This model implements the PatchCore algorithm which uses a memory bank of patch features for anomaly detection. Features are extracted from a pretrained CNN backbone and stored in a memory bank. Anomalies are detected by comparing test image patches with the stored features using nearest neighbor search.
The model works in two phases: 1. Training: Extract and store patch features from normal training images 2. Inference: Compare test image patches against stored features to detect
anomalies
- Parameters:
layers (
Sequence[str]) – Names of layers to extract features from.backbone (
str) – Name of the backbone CNN network. Defaults to"wide_resnet50_2".pre_trained (
bool) – Whether to use pre-trained backbone weights. Defaults toTrue.num_neighbors (
int) – Number of nearest neighbors to use. Defaults to9.
Example
>>> from anomalib.models.image.patchcore.torch_model import PatchcoreModel >>> model = PatchcoreModel( ... backbone="wide_resnet50_2", ... layers=["layer2", "layer3"], ... pre_trained=True, ... num_neighbors=9 ... ) >>> input_tensor = torch.randn(32, 3, 224, 224) >>> output = model(input_tensor)
- feature_extractor#
CNN feature extractor.
- Type:
- feature_pooler#
Average pooling layer.
- Type:
- anomaly_map_generator#
Generates anomaly heatmaps.
- Type:
- memory_bank#
Storage for patch features from training.
- Type:
Notes
The model requires no optimization/backpropagation as it uses a pretrained backbone and nearest neighbor search.
See also
anomalib.models.image.patchcore.lightning_model.Patchcore:Lightning implementation of the PatchCore model
anomalib.models.image.patchcore.anomaly_map.AnomalyMapGenerator:Anomaly map generation for PatchCore
anomalib.models.components.KCenterGreedy:Coreset subsampling using k-center-greedy approach
- compute_anomaly_score(patch_scores, locations, embedding)#
Compute image-level anomaly scores.
Implements the paper’s weighted scoring mechanism that considers both the distance to nearest neighbors and the local neighborhood structure in the memory bank.
- Parameters:
- Returns:
Image-level anomaly scores.
- Return type:
Example
>>> patch_scores = torch.randn(32, 49) # 7x7 patches >>> locations = torch.randint(0, 1000, (32, 49)) >>> embedding = torch.randn(32 * 49, 512) >>> scores = model.compute_anomaly_score(patch_scores, locations, ... embedding) >>> scores.shape torch.Size([32])
Note
When
num_neighbors=1, returns the maximum patch score directly. Otherwise, computes weighted scores using neighborhood information.
- static euclidean_dist(x, y)#
Compute pairwise Euclidean distances between two sets of vectors.
Implements an efficient matrix computation of Euclidean distances between all pairs of vectors in
xandywithout usingtorch.cdist().- Parameters:
- Returns:
- Distance matrix of shape
(n, m)where element (i,j)is the distance between rowiofxand rowjofy.
- Distance matrix of shape
- Return type:
Example
>>> x = torch.randn(100, 512) >>> y = torch.randn(50, 512) >>> distances = PatchcoreModel.euclidean_dist(x, y) >>> distances.shape torch.Size([100, 50])
Note
This implementation avoids using
torch.cdist()for better compatibility with ONNX export and OpenVINO conversion.
- forward(input_tensor)#
Process input tensor through the model.
During training, returns embeddings extracted from the input. During inference, returns anomaly maps and scores computed by comparing input embeddings against the memory bank.
- Parameters:
input_tensor (
Tensor) – Input images of shape(batch_size, channels, height, width).- Returns:
- During training, returns embeddings.
During inference, returns
InferenceBatchcontaining anomaly maps and scores.
- Return type:
Example
>>> model = PatchcoreModel(layers=["layer1"]) >>> input_tensor = torch.randn(32, 3, 224, 224) >>> output = model(input_tensor) >>> if model.training: ... assert isinstance(output, torch.Tensor) ... else: ... assert isinstance(output, InferenceBatch)
- generate_embedding(features)#
Generate embedding by concatenating multi-scale feature maps.
Combines feature maps from different CNN layers by upsampling them to a common size and concatenating along the channel dimension.
- Parameters:
features (
dict[str,Tensor]) – Dictionary mapping layer names to feature tensors extracted from the backbone CNN.- Returns:
- Concatenated feature embedding of shape
(batch_size, num_features, height, width).
- Return type:
Example
>>> features = { ... "layer1": torch.randn(32, 64, 56, 56), ... "layer2": torch.randn(32, 128, 28, 28) ... } >>> embedding = model.generate_embedding(features) >>> embedding.shape torch.Size([32, 192, 56, 56])
- nearest_neighbors(embedding, n_neighbors)#
Find nearest neighbors in memory bank for input embeddings.
Uses brute force search with Euclidean distance to find the closest matches in the memory bank for each input embedding. Processes embeddings in chunks to reduce memory usage for large embedding sets.
- Parameters:
- Returns:
- Tuple containing:
Distances to nearest neighbors (shape:
(n, k))Indices of nearest neighbors (shape:
(n, k))
where
nis number of query embeddings andkisn_neighbors.
- Return type:
Example
>>> embedding = torch.randn(100, 512) >>> # Assuming memory_bank is already populated >>> scores, locations = model.nearest_neighbors(embedding, n_neighbors=5) >>> scores.shape, locations.shape (torch.Size([100, 5]), torch.Size([100, 5]))
- static reshape_embedding(embedding)#
Reshape embedding tensor for patch-wise processing.
Converts a 4D embedding tensor into a 2D matrix where each row represents a patch embedding vector.
- Parameters:
embedding (
Tensor) – Input embedding tensor of shape(batch_size, embedding_dim, height, width).- Returns:
- Reshaped embedding tensor of shape
(batch_size * height * width, embedding_dim).
- Return type:
Example
>>> embedding = torch.randn(32, 512, 7, 7) >>> reshaped = PatchcoreModel.reshape_embedding(embedding) >>> reshaped.shape torch.Size([1568, 512])
- subsample_embedding(sampling_ratio, embeddings=None)#
Subsample the memory_banks embeddings using coreset selection.
Uses k-center-greedy coreset subsampling to select a representative subset of patch embeddings to store in the memory bank.
- Parameters:
- Return type:
Example
>>> model.memory_bank = torch.randn(1000, 512) >>> model.subsample_embedding(sampling_ratio=0.1) >>> model.memory_bank.shape torch.Size([100, 512])