WinCLIP#
Architecture#
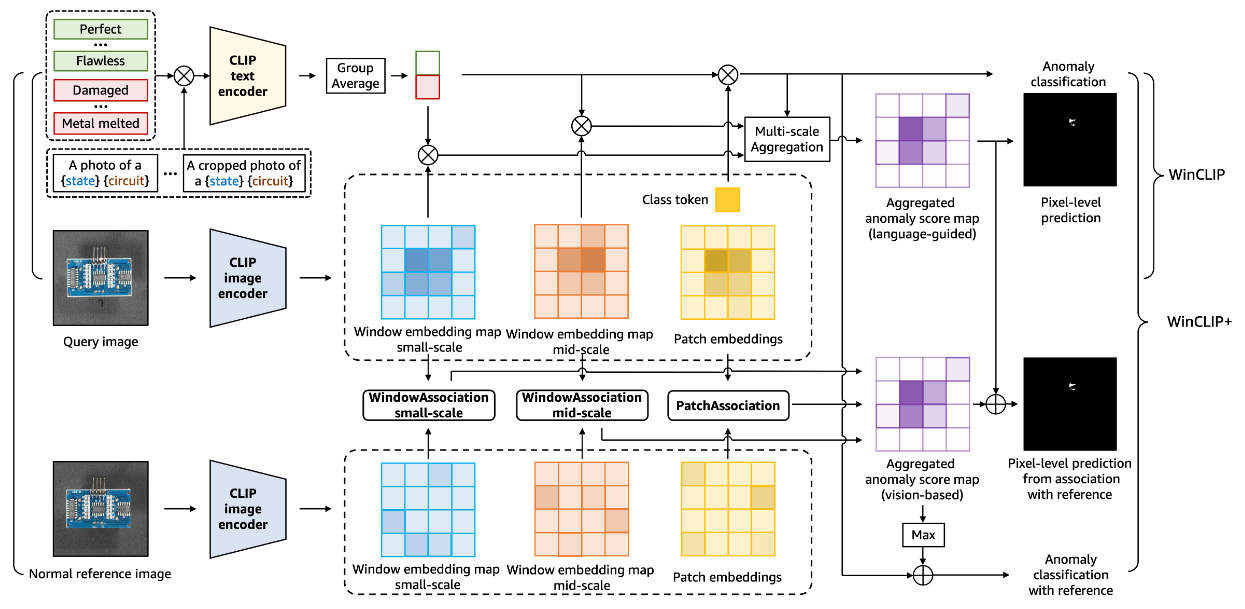
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation.
This module implements the WinCLIP model for zero-shot and few-shot anomaly detection using CLIP embeddings and a sliding window approach.
The model can perform both anomaly classification and segmentation tasks by comparing image regions with normal reference examples through CLIP embeddings.
Example
>>> from anomalib.data import MVTecAD
>>> from anomalib.engine import Engine
>>> from anomalib.models.image import WinClip
>>> datamodule = MVTecAD(root="./datasets/MVTecAD")
>>> model = WinClip()
>>> Engine.test(model=model, datamodule=datamodule)
- Paper:
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation https://arxiv.org/abs/2303.14814
See also
WinClip: Main model class for WinCLIP-based anomaly detectionWinClipModel: PyTorch implementation of the WinCLIP model
- class anomalib.models.image.winclip.lightning_model.WinClip(class_name=None, k_shot=0, scales=(2, 3), few_shot_source=None, pre_processor=True, post_processor=True, evaluator=True, visualizer=True)#
Bases:
AnomalibModuleWinCLIP Lightning model.
This model implements the WinCLIP algorithm for zero-/few-shot anomaly detection using CLIP embeddings and a sliding window approach. The model can perform both anomaly classification and segmentation by comparing image regions with normal reference examples.
- Parameters:
class_name (
str|None) – Name of the object class used in the prompt ensemble. If not provided, will try to infer from the datamodule or use “object” as default. Defaults toNone.k_shot (
int) – Number of reference images to use for few-shot inference. If 0, uses zero-shot approach. Defaults to0.scales (
tuple) – Scales of sliding windows used for multiscale anomaly detection. Defaults to(2, 3).few_shot_source (
Path|str|None) – Path to folder containing reference images for few-shot inference. If not provided, reference images are sampled from training data. Defaults toNone.pre_processor (
Module|bool) – Pre-processor instance or flag to use default. Used to pre-process input data before model inference. Defaults toTrue.post_processor (
Module|bool) – Post-processor instance or flag to use default. Used to post-process model predictions. Defaults toTrue.evaluator (
Evaluator|bool) – Evaluator instance or flag to use default. Used to compute metrics. Defaults toTrue.visualizer (
Visualizer|bool) – Visualizer instance or flag to use default. Used to create visualizations. Defaults toTrue.
Example
>>> from anomalib.models.image import WinClip >>> # Zero-shot approach >>> model = WinClip() >>> # Few-shot with 5 reference images >>> model = WinClip(k_shot=5) >>> # Custom class name >>> model = WinClip(class_name="transistor")
Notes
Input image size is fixed at 240x240 and cannot be modified
Uses a custom normalization transform specific to CLIP
See also
WinClipModel: PyTorch implementation of the core modelPostProcessor: Default post-processor used by WinCLIP
- collect_reference_images(dataloader)#
Collect reference images for few-shot inference.
Iterates through the training dataset until the required number of reference images (specified by
k_shot) are collected.- Parameters:
dataloader (
DataLoader) – DataLoader to collect reference images from- Returns:
Tensor containing the collected reference images
- Return type:
- static configure_optimizers()#
Configure optimizers.
WinCLIP doesn’t require optimization, therefore returns no optimizers.
- Return type:
- static configure_post_processor()#
Configure the default post-processor for WinCLIP.
- Returns:
Default post-processor instance
- Return type:
- classmethod configure_pre_processor(image_size=None)#
Configure the default pre-processor used by the model.
- property learning_type: LearningType#
Get the learning type of the model.
- Returns:
LearningType.FEW_SHOTifk_shot > 0, elseLearningType.ZERO_SHOT
- Return type:
LearningType
- setup(stage)#
Setup WinCLIP model.
This method: - Sets the class name used in the prompt ensemble - Collects text embeddings for zero-shot inference - Collects reference images for few-shot inference if
k_shot > 0Note
This hook is called before the model is moved to the target device.
- Return type:
PyTorch model implementation of WinCLIP for zero-/few-shot anomaly detection.
This module provides the core PyTorch model implementation of WinCLIP, which uses CLIP embeddings and a sliding window approach to detect anomalies in images.
The model can operate in both zero-shot and few-shot modes:
- Zero-shot: No reference images needed
- Few-shot: Uses k reference normal images for better context
Example
>>> from anomalib.models.image.winclip.torch_model import WinClipModel
>>> model = WinClipModel()
>>> # Zero-shot inference
>>> prediction = model(image)
>>> # Few-shot with reference images
>>> model = WinClipModel(reference_images=normal_images)
- Paper:
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation https://arxiv.org/abs/2303.14814
See also
WinClip: Lightning model wrapperprompting: Prompt ensemble generationutils: Utility functions for scoring and aggregation
- class anomalib.models.image.winclip.torch_model.WinClipModel(class_name=None, reference_images=None, scales=(2, 3), apply_transform=False)#
Bases:
DynamicBufferMixin,BufferListMixin,ModulePyTorch module that implements the WinClip model for image anomaly detection.
The model uses CLIP embeddings and a sliding window approach to detect anomalies in images. It can operate in both zero-shot and few-shot modes.
- Parameters:
class_name (
str|None) – Name of the object class used in prompt ensemble. Defaults toNone.reference_images (
Tensor|None) – Reference images of shape(K, C, H, W). Defaults toNone.scales (
tuple) – Scales of sliding windows for multi-scale detection. Defaults to(2, 3).apply_transform (
bool) – Whether to apply default CLIP transform to inputs. Defaults toFalse.
- clip#
CLIP model for image and text encoding.
- Type:
CLIP
- masks#
Masks for sliding window locations.
- Type:
list[torch.Tensor] | None
- _text_embeddings#
Text embeddings for prompt ensemble.
- Type:
torch.Tensor | None
- _visual_embeddings#
Multi-scale reference embeddings.
- Type:
list[torch.Tensor] | None
- _patch_embeddings#
Patch embeddings for reference images.
- Type:
torch.Tensor | None
Example
>>> from anomalib.models.image.winclip.torch_model import WinClipModel >>> # Zero-shot mode >>> model = WinClipModel(class_name="transistor") >>> image = torch.rand(1, 3, 224, 224) >>> prediction = model(image) >>> >>> # Few-shot mode with reference images >>> ref_images = torch.rand(3, 3, 224, 224) >>> model = WinClipModel( ... class_name="transistor", ... reference_images=ref_images ... )
- encode_image(batch)#
Encode batch of images to get image, window and patch embeddings.
The image and patch embeddings are obtained by passing images through the model. Window embeddings are obtained by masking feature map and passing through transformer. A forward hook retrieves intermediate feature map to share computation.
- Parameters:
batch (
Tensor) – Input images of shape(N, C, H, W).- Returns:
- Tuple containing:
Image embeddings of shape
(N, D)Window embeddings list, each of shape
(N, W, D)Patch embeddings of shape
(N, P, D)
where
Dis embedding dimension,Wis number of windows, andPis number of patches.
- Return type:
Examples
>>> model = WinClipModel() >>> model.prepare_masks() >>> batch = torch.rand((1, 3, 240, 240)) >>> outputs = model.encode_image(batch) >>> image_embeddings, window_embeddings, patch_embeddings = outputs >>> image_embeddings.shape torch.Size([1, 640]) >>> [emb.shape for emb in window_embeddings] [torch.Size([1, 196, 640]), torch.Size([1, 169, 640])] >>> patch_embeddings.shape torch.Size([1, 225, 896])
- forward(batch)#
Forward pass to get image and pixel anomaly scores.
- Parameters:
batch (
Tensor) – Input images of shape(batch_size, C, H, W).- Returns:
- Either tuple containing:
Image scores of shape
(batch_size,)Pixel scores of shape
(batch_size, H, W)
Or
InferenceBatchwith same information.
- Return type:
- property patch_embeddings: Tensor#
Get model’s patch embeddings.
- Returns:
Patch embeddings used for few-shot inference.
- Return type:
- Raises:
RuntimeError – If patch embeddings not collected via
setup.
- setup(class_name=None, reference_images=None)#
Setup WinCLIP model with class name and/or reference images.
The setup stage collects text and visual embeddings used during inference: - Text embeddings for zero-shot inference if
class_nameprovided - Visual embeddings for few-shot inference ifreference_imagesprovided Thek_shotattribute is updated based on number of reference images.This method is called by constructor but can also be called manually to update embeddings after initialization.
- Parameters:
- Return type:
Examples
>>> model = WinClipModel() >>> model.setup("transistor") >>> model.text_embeddings.shape torch.Size([2, 640])
>>> ref_images = torch.rand(2, 3, 240, 240) >>> model = WinClipModel() >>> model.setup("transistor", ref_images) >>> model.k_shot 2 >>> model.visual_embeddings[0].shape torch.Size([2, 196, 640])
>>> model = WinClipModel("transistor") >>> model.k_shot 0 >>> model.setup(reference_images=ref_images) >>> model.k_shot 2
>>> model = WinClipModel( ... class_name="transistor", ... reference_images=ref_images ... ) >>> model.text_embeddings.shape torch.Size([2, 640]) >>> model.visual_embeddings[0].shape torch.Size([2, 196, 640])
- property text_embeddings: Tensor#
Get model’s text embeddings.
- Returns:
Text embeddings used for zero-shot inference.
- Return type:
- Raises:
RuntimeError – If text embeddings not collected via
setup.
- property transform: Compose#
Get model’s transform pipeline.
Retrieves transforms from CLIP backbone and prepends
ToPILImagetransform since original transforms expect PIL images.- Returns:
Transform pipeline for preprocessing images.
- Return type:
Compose
- property visual_embeddings: list[Tensor]#
Get model’s visual embeddings.
- Returns:
Visual embeddings used for few-shot inference.
- Return type:
- Raises:
RuntimeError – If visual embeddings not collected via
setup.