GeneralAD#
Architecture#
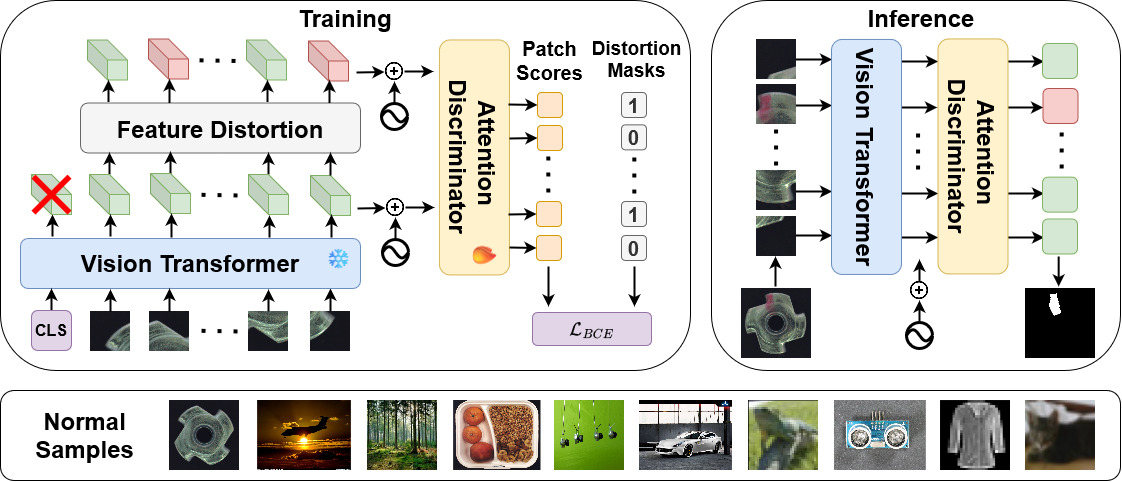
Lightning implementation of GeneralAD.
- class anomalib.models.image.general_ad.lightning_model.GeneralAD(backbone='vit_large_patch14_dinov2.lvd142m', layers=(24,), hidden_dim=2048, lr=0.0005, lr_decay_factor=0.2, weight_decay=1e-05, epochs=160, noise_std=0.25, dsc_layers=1, dsc_heads=4, dsc_dropout=0.1, num_fake_patches=-1, fake_feature_type='random', top_k=10, pre_trained=True, pre_processor=True, post_processor=True, evaluator=True, visualizer=True)#
Bases:
AnomalibModuleGeneralAD Lightning module.
- Parameters:
backbone (
str) – Timm backbone used as frozen feature extractor.layers (
Sequence[int]) – Backbone stages or transformer blocks used for patch features.hidden_dim (
int) – Hidden size of the patch discriminator.lr (
float) – Optimizer learning rate.lr_decay_factor (
float) – Final cosine annealing ratio.weight_decay (
float) – Optimizer weight decay.epochs (
int) – Number of epochs used to parameterize the LR scheduler.noise_std (
float) – Standard deviation for synthetic anomalous features.dsc_layers (
int) – Number of attention blocks in the discriminator.dsc_heads (
int) – Number of attention heads in the discriminator.dsc_dropout (
float) – Dropout rate in the discriminator.num_fake_patches (
int) – Maximum number of perturbed patches per image.fake_feature_type (
Literal['random','attn','copy_out','shuffle','randshuffle','copy_out_and_random','copy_out_and_attn','shuffle_and_random','shuffle_and_attn','randshuffle_and_random','randshuffle_and_attn']) – Strategy for generating pseudo anomalies.top_k (
int) – Number of highest patch scores to average for image scoring.pre_trained (
bool) – Whether to use pretrained backbone weights.pre_processor (
PreProcessor|bool) – Optional anomalib pre-processor.post_processor (
PostProcessor|bool) – Optional anomalib post-processor.visualizer (
Visualizer|bool) – Optional anomalib visualizer.
- static configure_evaluator()#
Configure validation and test metrics for checkpoint selection.
Upstream GeneralAD selects the best checkpoint using image-level AUROC on the validation loop. In our MVTec reproduction, validation is configured as
SAME_AS_TESTto mirror the upstream behavior, so monitoringimage_AUROChere reproduces the same selection rule.- Return type:
- classmethod configure_pre_processor(image_size=None)#
Configure the default pre-processor.
- Return type:
- property learning_type: LearningType#
GeneralAD is a one-class anomaly detection model.
- training_step(batch, *args, **kwargs)#
Run the self-supervised GeneralAD training step.
PyTorch model for the GeneralAD algorithm.
GeneralAD learns a patch-wise discriminator on top of frozen features extracted from a pretrained backbone. During training it creates pseudo-anomalous patch features using noise injection and patch shuffling/copying. During inference the discriminator scores each patch and the highest patch scores are aggregated into an image-level anomaly score.
- class anomalib.models.image.general_ad.torch_model.AttentionBlock(embed_dim, hidden_dim, num_heads, dropout=0.0)#
Bases:
ModuleTransformer block used in the patch discriminator.
- class anomalib.models.image.general_ad.torch_model.EVAFeatureExtractor(backbone, layers, image_size, pre_trained=True)#
Bases:
ModuleExtract patch features from EVA-style transformer backbones.
- class anomalib.models.image.general_ad.torch_model.GeneralADModel(backbone='vit_large_patch14_dinov2.lvd142m', layers=(24,), hidden_dim=2048, noise_std=0.25, dsc_layers=1, dsc_heads=4, dsc_dropout=0.1, image_size=(518, 518), num_fake_patches=-1, fake_feature_type='random', top_k=10, pre_trained=True)#
Bases:
ModuleCore GeneralAD model.
- extract_features(images)#
Extract patch features and optional class-attention maps.
- forward(images)#
Predict anomaly scores and maps.
- Return type:
- class anomalib.models.image.general_ad.torch_model.PatchDiscriminator(embed_dim, hidden_dim, num_patches, num_layers=1, num_heads=12, dropout_rate=0.0)#
Bases:
ModuleAttention-based patch discriminator.