PatchFlow#
Architecture#
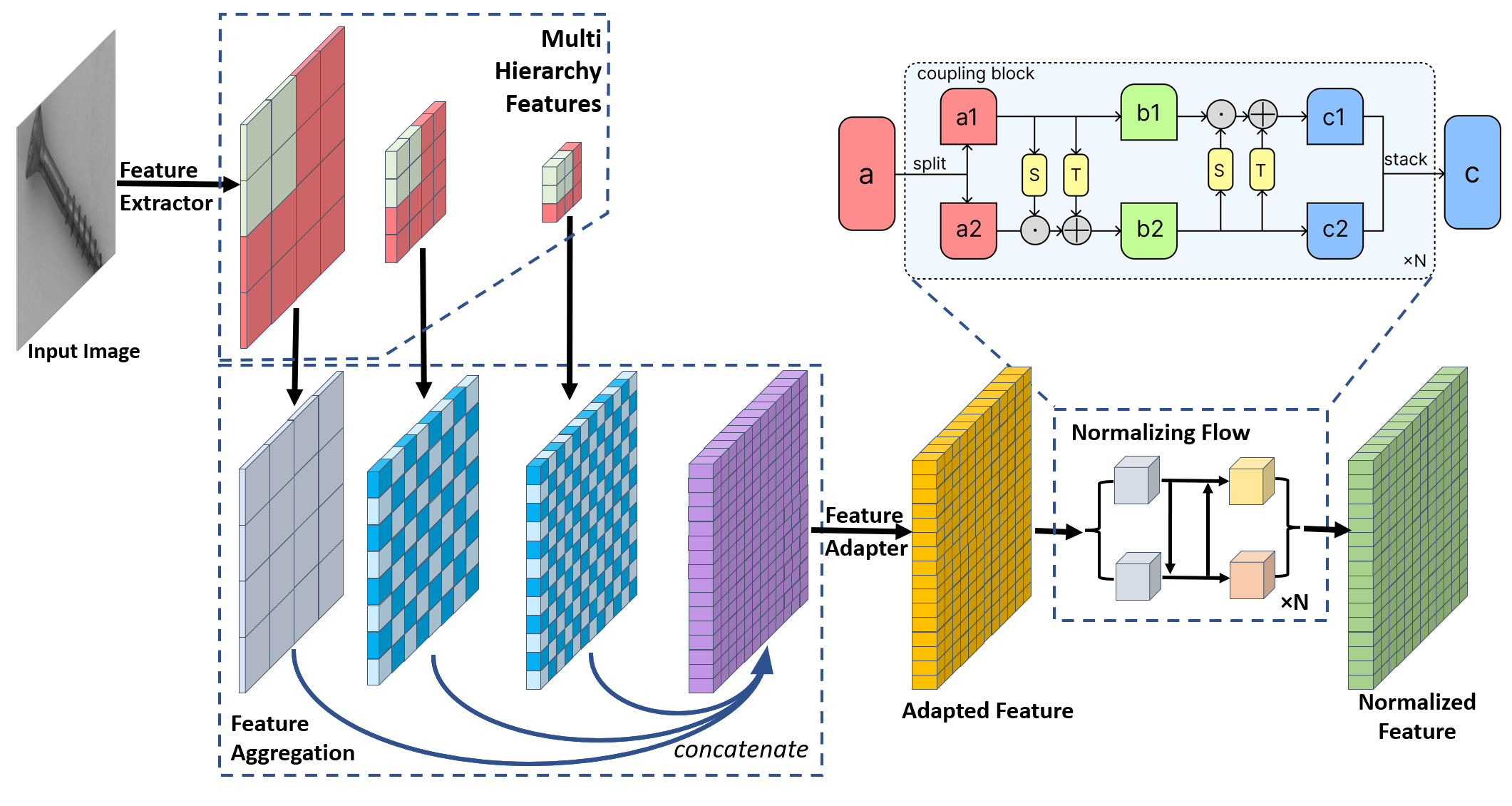
PatchFlow Lightning Model Implementation.
This model implements the PatchFlow algorithm for anomaly detection and localization. PatchFlow models the distribution of patch-level feature embeddings using a learnable normalizing flow.
The model extracts patch embeddings from intermediate layers of a pretrained backbone. It then passes them through a feature adaptor, which projects and aligns features into a space suited for density estimation. These patch features are then transformed by a flow-based density estimator that learns the distribution of normal data.
During inference, the model computes the likelihood of each patch under the learned flow. Low-likelihood patches indicate anomalies. The patch-level scores are aggregated to produce both an image-level anomaly score and a pixel-wise anomaly map.
Paper: https://arxiv.org/abs/2602.05238
Example
>>> from anomalib.data import MVTecAD
>>> from anomalib.models import Patchflow
>>> from anomalib.engine import Engine
>>> datamodule = MVTecAD()
>>> model = Patchflow()
>>> engine = Engine()
>>> engine.fit(model, datamodule=datamodule)
>>> predictions = engine.predict(model, datamodule=datamodule)
- class anomalib.models.image.patchflow.lightning_model.Patchflow(backbone='tf_efficientnet_b5', pre_trained=True, flow_steps=1, flow_feature_dim=128, num_scales=3, patch_size=3, flow_hidden_dim=128, crop_size=None, lr=0.001, weight_decay=0.0001, pre_processor=True, post_processor=True, evaluator=True, visualizer=True)#
Bases:
AnomalibModuleLightning Module for the PatchFlow algorithm.
- Parameters:
backbone (
str) – Backbone network. A timm model name or a DINOv2 model name. Defaults to"tf_efficientnet_b5".pre_trained (
bool) – Whether to use pre-trained backbone weights. Defaults toTrue.flow_steps (
int) – Number of coupling blocks in the normalizing flow. Defaults to1.flow_feature_dim (
int) – Channel dimension after the feature adaptor. Defaults to128.num_scales (
int) – Number of input resolutions for multi-scale extraction. Defaults to3.patch_size (
int) – Kernel size of the AvgPool for local aggregation. Defaults to3.flow_hidden_dim (
int) – Hidden channels in the flow subnet. Defaults to128.crop_size (
tuple[int,int] |None) – Optional center crop size(H, W). When set, the input is center-cropped before feature extraction and the anomaly map is padded with value-1back to the original input size. Defaults toNone.lr (
float) – Learning rate for the Adam optimizer. Defaults to0.001.weight_decay (
float) – Weight decay (L2 penalty) for the Adam optimizer. Defaults to0.0001.pre_processor (
PreProcessor|bool) – Pre-processor instance or boolean. Defaults toTrue.post_processor (
PostProcessor|bool) – Post-processor instance or boolean. Defaults toTrue.evaluator (
Evaluator|bool) – Evaluator instance or boolean. Defaults toTrue.visualizer (
Visualizer|bool) – Visualizer instance or boolean. Defaults toTrue.
- static configure_evaluator()#
Configure default evaluator with image/pixel AUROC and F1.
- Return type:
- static configure_pre_processor(image_size=None)#
Configure the default pre-processor for PatchFlow.
Matches the official repo transforms (Resize + ImageNet Normalize). BOX-LEO/PatchFlow
Note
The default
(768, 768)is not divisible by the DINOv2 ViT patch size (14). When a DINOv2 backbone is used, the torch model automatically center-crops the input to the nearest patch-aligned size, so no manualcrop_sizeis required.
- property learning_type: LearningType#
Return the learning type of the model.
- Returns:
One-class learning.
- Return type:
LearningType
- on_load_checkpoint(checkpoint)#
Make checkpoints trained before the timm-encoder migration loadable.
When using a DINOv2 backbone, the frozen feature extractor was migrated from a custom Vision Transformer to a frozen
TimmFeatureExtractor. The legacy encoder weights are dropped and replaced by the current timm encoder weights so the strict state-dict load still succeeds. Seerestore_frozen_encoder_weights().
- training_step(batch, *args, **kwargs)#
Perform the training step.
PatchFlow Torch Model Implementation.
PatchFlow fuses multi-scale backbone features into a single tensor, compresses them with a 1x1 convolution adaptor, and runs a single normalizing flow for anomaly detection.
- class anomalib.models.image.patchflow.torch_model.PatchflowModel(input_size, backbone='tf_efficientnet_b5', pre_trained=True, flow_steps=1, flow_feature_dim=128, num_scales=3, patch_size=3, flow_hidden_dim=128, crop_size=None)#
Bases:
ModulePatchFlow model for anomaly detection.
Extracts multi-scale features from a frozen backbone, fuses them into a single tensor, adapts the channel dimension, and passes through a single normalizing flow.
- Parameters:
backbone (
str) – timm model name or DINOv2 model name (e.g."tf_efficientnet_b5"or"vit_base_patch14_dinov2").pre_trained (
bool) – Whether to use pre-trained backbone weights.flow_steps (
int) – Number of coupling blocks in the normalizing flow.flow_feature_dim (
int) – Channel dimension after the feature adaptor.num_scales (
int) – Number of input resolutions for multi-scale extraction.patch_size (
int) – Kernel size of the AvgPool for local aggregation.flow_hidden_dim (
int) – Hidden channels in the flow subnet.crop_size (
tuple[int,int] |None) – Optional center crop size(H, W)applied before feature extraction. The anomaly map is padded with-1back toinput_size. Defaults toNone(no cropping).
Loss function for the PatchFlow Model Implementation.
PatchFlow uses a single normalizing flow on fused features, so the loss
operates on a single (B, C, H, W) hidden variable tensor and (B,)
jacobians, normalized by the flattened feature dimension.
- class anomalib.models.image.patchflow.loss.PatchflowLoss(*args, **kwargs)#
Bases:
ModulePatchFlow Loss Module.
Computes the negative log-likelihood loss normalized by the feature dimension of the fused hidden variable tensor.
- static forward(hidden_variables, jacobians)#
Calculate the PatchFlow loss.
PatchFlow Anomaly Map Generator Implementation.
This module generates anomaly heatmaps from the single fused hidden variable tensor produced by the PatchFlow normalizing flow.
- class anomalib.models.image.patchflow.anomaly_map.AnomalyMapGenerator(input_size)#
Bases:
ModuleGenerate anomaly heatmap from PatchFlow hidden variables.
Unlike FastFlow which averages maps from multiple flow blocks, PatchFlow operates on a single fused tensor.
- Parameters:
input_size (
ListConfig|tuple) – Target size(height, width)for the anomaly map.